One of the most fundamental concepts of ASP.Net – and indeed of any transactional web development technology – is the concept of Postbacks. That is, the idea that an interactive web page may be used by inputting information via the interface presented at the client (i.e. web browser) side of the transaction, and then ‘submitting’ the page so-influenced by user input for processing by the web server. Web users are highly familiar with this concept from a user perspective – whether they’re shopping at Amazon, commenting on stories on the BBC News Site, posting threads on web forums, or whatever, it’s widely understood that in order to affect any change whatsoever with an interactive website users need to input what they want at the browser UI, and ‘post’ the page back in some way (often by simply hitting a button marked ‘submit’, but also in may other ways specific to context).
For web developers, facilitating this type of interaction with users presents many challenges, not least of which is the fact that the web is essentially a ‘stateless’ medium. Which is to say that each time an interactive web page is ‘submitted’ for processing, from the perspective of the web server it’s as if it is the first time it has interacted with the user in question, and so everything about the transaction that is being attempted must be included in the page that has been submitted (including information that, from the user’s perspective, they may have submitted several steps previously, e.g., they may have entered their Amazon user account name and password previously, and have added several items to their ‘basket’ in the meantime, but they don’t expect to have to enter their credentials again when they click ‘Purchase’ as the final step in the process – they expect the page to somehow have ‘remembered’ that they had provided that information already).
This article is about how ASP.Net handles Postbacks in a stateless medium, and focuses in particular on the .Net-specific concept of the page life cycle of an ASPX page.
As mentioned above, facilitating interaction between website owners and website users, and between website users with one another, presents many challenges, whatever development technology you’re using. The HTTP protocol upon which the internet was originally based, and that it still relies heavily upon today, was really designed for allowing people to share ‘static’ content with one another. The web, as it was originally envisioned, allowed users to share simple text files of a fixed content with their peers. Each request for a ‘page’ would result in the exact same HTML being rendered, until and unless the publisher of that page deliberately changed the content manually. For this type of interaction, a stateless communication protocol is perfectly suitable : user requests a page, user gets that page; simple. However, that original concept isn’t how users expect the web to work any more. Today, they expect to be able to interact with, not merely consume, the content of the websites they use. Providing this type of interactivity has involved developers finding ways to allow an essentially static medium to somehow ‘remember’ individual users, and interact with them in ways that make sense within the context of those preceding interactions. ‘Remembering’ previously-encountered information in this way is known as ‘persisting state’.
The main tool that ASP.Net provides to facilitate the illusion of persisting state in interactive web pages is the concept of an ASPX page. Simply put, an ASPX page, also known as a ‘web form’, is a type of container that can hold several discrete types of object – collectively known as ‘controls’ – that allow a user to input information, or otherwise interact with the page. The types of control that can be placed in an ASPX page (which I’ll refer to simply as a ‘page’ from here on in) are many any varied. There is, for example, a particular class of objects known as ‘web controls’, which are defined in the System.Web.UI.WebControls .net framework namespace. These controls provide many ready-made interactive elements, such as text boxes, radio buttons, drop down lists, and others, that retain the values entered into them by users across different postbacks of the page. Developers can additionally create more complex interactive elements of their own design, known as ‘user controls’. User controls employ many of the same paradigms as web controls, but require more developer knowledge to build, whilst providing a greater degree of control over visual presentation for the developer. The last thing that developers should know about controls (of whatever type) is that they may facilitate custom Events, specific to the type of control. That is, they can be designed/used in such a way as to ensure that a postback occurs and that specific code runs at the web server in response to users interacting with the controls in a certain pre-defined way. E.g., textboxes may be designed to respond to users entering text in them, and buttons and images may be designed to respond to being clicked, etc.
The way that ASPX pages manage the feat of appearing to persisting data within the confines of the stateless medium of the internet is by using something called ViewState. In essence, ViewState is a special type of non-visible or ‘hidden’ control, contained within the ASPX page, whose job, amongst other things, is to keep track of all of the data entered in and required by each of the other data-dependent controls on the web form. It is the ViewState mechanism that allows a web server running Internet Information Services (IIS) to interpret the virtual ‘state’ of a page (a ‘state’ that was potentially built up over several preceding postbacks). If you ever look at the underlying page source of an ASPX page as it is rendered in a browser, you may well see something that looks like this somewhere in the middle of the HTML:
<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="/wEPDwUJNjI0NjY1NDA2DxYCHgpNeVByb3BlcnR5BQMxMjNkZNsT9/JHdta88TymHVqnYrr7vzIS8vtD3DxRcAt1+MLp" />
This is the page's ViewState. It’s not visible to the user (hence the type="hidden" attribute of the input HTML element tag), but it is nonetheless very important to maintaining the illusion that the system the user is interacting with ‘remembers’ key aspects of the user’s preceding interaction, thereby providing the illusion of persisting state. The value contained in the value="......" tag is a serialised representation of the data used by other controls in the form. There’s a lot more to ViewState, and indeed optimising it is a whole other topic in itself that I’ll perhaps write about another time. Within the scope of this discussion, though, it can be understood to be a serialised hash table, that ‘stores’ named Properties of controls on the page and their values across different postbacks of the page. There’s another type of object, known as ControlState, that performs a similar job to ViewState, but which specifically exists to track properties of controls regardless of any other settings a developer may choose to implement. The main distinction between ViewState and ControlState is that, whilst ViewState may optionally be developer-configured to be disabled, ControlState cannot; where ViewState doesn’t exist ControlState is necessary to do all the work of tracking control properties on its own.
So, to recap, ASPX pages contain various types of control, and the page itself may be submitted by users to the web server for further processing in a process known as making a postback. From the users’ perspective, making a postback conceptually involves ‘submitting’ the page, thereby performing some data-driven action, such as processing an order, making a post on a forum, etc., in a way that is abstracted from and invisible to the user. Now, let’s look at what actually happens from a developer perspective at the web server when such a postback actually takes place.
As well as allowing developers to design the visual and non-visual elements of the user interface, at design time ASPX pages also include a separate developer tool known as the Code Behind element of the page. This part of the design may be thought of as representing that part of the design that gets executed at the web server end (as opposed to anything that happens in the users’ browsers). The Code Behind part of the page facilitates interaction between disconnected users submitting pages via postbacks out in the stateless web, and those ‘back end’ parts of the system that turn those user postbacks into meaningful actions, such as facilitating transactions with underlying databases. For example, this is the part of the wider system that allows product orders placed by users on commercial websites and posts made on internet forums to be turned into records in a more permanently-stored medium, such as a relational database. The way that the Code Behind element of the page facilitates this interaction relies heavily on several of those elements already touched upon, as well as some others that will be discussed below. In summary, whenever a postback takes place, the following Events will take place in the order presented below within the Code Behind:
1. Pre-Init
2. Init
3. InitComplete
4. Pre-Load
5. Load
6. Control Events
7. LoadComplete
8. PreRender
9. PreRenderComplete
10. SaveStateComplete
11. Render*
12. Unload
* Render isn’t an Event per se, but a Protected Method that gets called for each control on the page at this point in the proceedings.
You can ‘subscribe’ to these Events by creating an appropriate ‘handler’ in the code behind. For example, to create a handler for the page Pre-Init Event, simply enter the following code:
C#:
void Page_PreInit(object sender, EventArgs e)
{
'Your custom code here
}
VB:
Private Sub Page_PreInit
(ByVal sender As Object, ByVal e As System.EventArgs)
Handles Me.PreInit
'Your custom code here
End Sub
In VB this is slightly easier than in C#, in that you need only select the Event you want to create a handler for from the drop-down list provided in the Visual Studio IDE, as demonstrated:
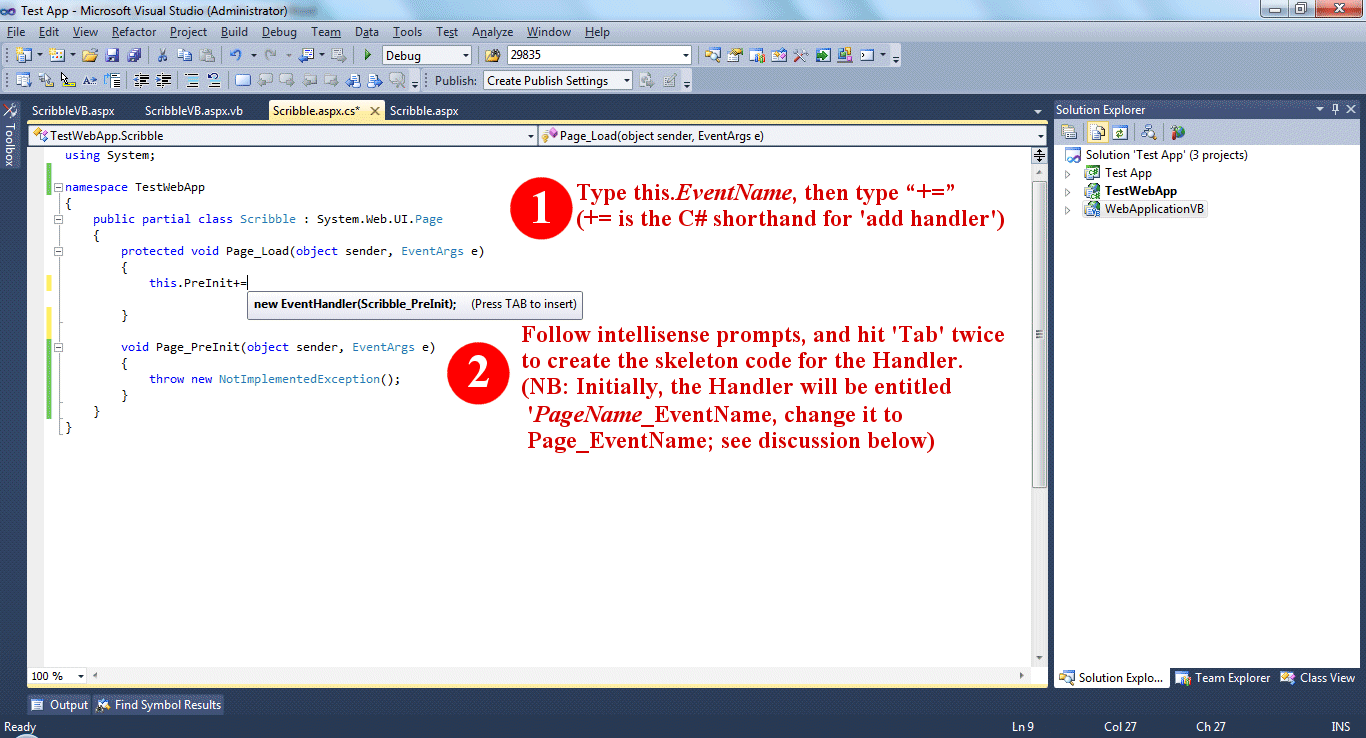
In C#, you either need to type the code by hand, or use the following method:
As noted in the C# version, using the above method will insert a Handler that is specific to the individual ASPX page, rather than one that is generally applicable to the System.Web.UI.Page object that all ASPX pages are based upon. This isn’t hugely problematic, but it is just a little neater and generates less code to be maintained if you rename the Handler using the nomenclature “Page_EventName” as suggested in the example, then delete the line reading:
this.PreInit += new EventHandler(WhateverYourPageIsCalled_PreInit);
that you used temporarily. You delete this line because upon renaming the Handler it becomes superfluous, because the ‘WhateverYourPageIsCalled_PreInit’ Handler to which it refers no longer exists, and because for exactly the same reason you’ll get a compilation error telling you about the Handler it refers to not existing. The reason that the “Page_EventName” Handler naming format is slightly more robust is that, provided you include the AutoEventWireup="true" attribute in the @ Page directive within the markup component of the ASPX page (and that attribute is included by default: see screen dump below), the ASPX page creates appropriate add handler code for any Page_Event handlers you define for you behind the scenes, rather than you having to maintain your own.
The VB environment is just a little bit smarter on this occasion than the C# one, and makes use of this useful feature without having to be overtly told to do so.
Moving on, the following sections describe what each of the Events you may create handlers for actually do, and provides suggestions for when you may want to use them.
Pre-Init
By the time this event runs, certain pre-processing will have occurred that allows the developer to decide what should happen at this juncture. Certain useful page properties will have been set, including the IsPostBack and IsCallBack properties. Respectively, these properties allow the developer to know whether the page is being ‘submitted’ for the first time by a user (in which case IsPostBack will be false), and whether the ‘submit’ action was triggered as a result of client script utilising a CallBack (a sort of mini-postback, involving processing of the code behind by the server without utilising the ‘submit’ mechanism or refreshing the page, used in AJAX-enabled applications). It’s possible in ASP.Net to submit the results from one ASPX page into the code behind for another ASPX page; if this is the case, then the IsCrossPagePostBack property of the page will be true at this stage.
As well as using the above properties to direct which Methods of your code behind to run, it’s common to use the Pre-Init handler to dynamically set any desired aspects of the page, such as setting the Theme or Master Page (both of which can affect the appearance and layout significantly), depending on the context.
It’s important to note that at this stage of the page life cycle, the controls on the page will not have had their values retrieved from the page’s ViewState yet. So, don’t use this handler to try and retrieve and act upon user input just yet.
Init
Each control on the page has an Init Event, which may be separately handled. Each of the individual controls’ Init Events will run before the page’s Init Event does.
MSDN advises to use this Event to “read and initialise” control properties, and also states that “controls typically turn on view state tracking immediately after they raise their Init event”. Be advised, however, that when I double-checked the actual behaviour under Framework version 4 and IIS 7 for writing this article, the specific behaviour I observed appeared to be as follows:
· You may validly set properties of controls during this Event only where the current page is not experiencing a PostBack (i.e., provided that this is the first time the user has submitted this page). Where you do initialise any properties here, you may expect those properties you initialise to be persisted to the control/page sent to the client during the first time the page is loaded only. i.e., if you set the ‘Text’ Property of a textbox during this Event, whatever you set that ‘Text’ Property to will be shown on the page as seen by the user, during the first processing of the page only, but not during any subsequent postbacks.
· ViewState is made active for individual controls during their own individual Init events, but be advised that setting values in ViewState directly is not possible within the Init event. NB: this is usually done to model generic ‘Properties’ within code behind pages, and the syntax takes the form:
ViewState("MyProperty") = "123" (VB)
ViewState["MyProperty"] = "123"; (C#).
· If you set default values for control properties in the ASPX page Markup, you can read those initialised properties during this Event. Any dynamically-initialised properties of user controls may also be read here (which might be important, depending on what you intended your user control to do). However, please note that whilst the above is all well and good, other behaviour observed during this event is a bit odd and counterintuitive. Specifically, you should be aware that, if this is a postback, and if the user has set a Property of a control, that user-set control property will not yet reflect the value contained by the control during this Event. Even worse, during this event any user-set controls will incorrectly appear to show the initial values they held when the page was ‘new’; so, control properties are not merely missing, but misleading and incorrect, during postbacks. Please remember this fact, and surround any code you may place within the Init event handler within a if (Page.IsPostBack) block to ensure that it behaves as you intend during all stages of the page’s life cycle.
InitComplete
Between the Init and InitComplete Events precisely one thing happens: ViewState tracking gets turned on. So, using the
ViewState["MyProperty"] = "123"
syntax mentioned earlier will cause values to be ‘permanently’ persisted to ViewState during this Event.
PreLoad
MSDN says that this Event runs after the page loads ViewState for itself and all child controls on the page. As noted above, however, I found that ViewState had already loaded during InitComplete. All postback data processing should have been completed by the time this Event runs.
Load
The page’s own Load Event runs, then the Load Event for each individual control on the page runs. Event handlers for the page and individual control’s Load events may be reliably used to set control properties programmatically during postbacks.
Load Event Handlers are a good place to initialise and open any database connections that may be required for further processing during the next stage.
Control Events
Individual control Event Handlers will run at this point in the page’s processing. So, if you’ve created a TextChanged event handler for a TextBox, this is the point in the page’s life cycle where that handler’s code would run.
LoadComplete
LoadComplete runs for the page only, not for individual controls. Place any code that relies on individual control event handling to be complete here (e.g., you may have code that determines whether a ‘Complete Transaction’ button is enabled here, depending on whether all necessary data has been entered in other controls first).
PreRender
An important part of what an ASPX page does is that it dynamically generates HTML markup pertinent to the present state of the page and its constituent controls (remember that discussion about how the web was originally conceived to be a static medium earlier? – well, it still is, and dynamic rendering of HTML in this way is the part of the whole ‘page life cycle’ process that makes it appear that a static medium is capable of generating interactive content based on user input). At this stage in the cycle, all controls have been added to the page, have been updated with the latest data from user input and server-side processing, and are ready to be rendered as HTML.
This Event may be used to make any final changes to control properties before final rendering takes place.
PreRenderComplete
This Event fires just after all data bound controls whose DataSourceID property has been set call their DataBind methods. Data Binding is outside the scope of this article.
SaveStateComplete
The SaveStateComplete Event fires after ViewState and ControlState have been finalised. MDSN advice says that any changes to controls made during or after this Event will be rendered, but will not be persisted during the next Postback. I didn’t find this to be the case – for example, setting the ‘Text’ property of a TextBox during this event will both change what gets rendered in the textbox when the page is presented to the user, and will persist the value set through to the next postback (and beyond). It just goes to show, it pays to check advice, even advice from the horse’s mouth, with each new release of the framework and IIS.
Render
Render isn’t an Event that can be handled, but a Protected Method that exists for each control on an ASPX page, that gets called for each control on the page at this point in the proceedings. This is the Method that is used to output the actual HTML that has been dynamically generated from all the foregoing processing within the page. The ASPX page passes a Framework object called a HTMLTextWriter into the Method as an argument. That HTMLTextWriter contains the page’s calculated HTML output specific to the present context of the control.
In 99% of all cases, the HTML generated by ASP.Net will be smart enough to ensure that what the developer intended to be presented to the user is what actually gets sent. However, there are a small number of cases where pages are just a little too complex, or where the evolving capabilities of the evermore complex browsers that are continually being developed falls out of sync with the most recent version of the .Net framework, leading to the ASP.Net rendering process sending HTML that is inappropriate for a particular user’s setup. In these cases, the Render Method may be overridden by the developer.
The following example shows one way of overriding the Render Method, that I used on a live project recently. The basic crux of the problem was that the ‘name’ attributes of the HTML tags rendered by the ASP.Net engine were of a particular format, and, for the purposes of working in harmony with another solution that I didn’t have access to the source code for, those name tags had to take on a different naming convention. I tried a couple of approaches, but the one that produced the most satisfactory results is reproduced below. The basic jist of the solution is that the Render Method is overridden in my custom user control, and HtmlTextWriter object that the Render Method takes as input from the ASPX page is tinkered with to ensure that each of the name attriubtes inserted by the ASP.Net engine is replaced by deliberately-set name tags chosen by the developer instead:
protected override void Render(HtmlTextWriter writer)
{
if (QuestionLabel != String.Empty && RenameControlsAsPerQuestionLabel == true)
{
StringBuilder sb = new StringBuilder();
StringWriter sw = new StringWriter(sb);
HtmlTextWriter hw = new HtmlTextWriter(sw);
base.Render(hw);
if (ResponseControlType == ControlTypeEnum.CheckboxGroup)
{
foreach (ResponseOption o in AvailableResponses)
{
sb.Replace(
"name=\"" + o.ResponseCheckBoxForCheckBoxGroupTypeQuestions.UniqueID + "\"",
"name=\"" + o.ResponseControlName + "\"");
}
}
else
{
sb.Replace("name=\"" + responseCtl.UniqueID + "\"", "name=\"" + QuestionLabel + "\"");
}
writer.Write(sb.ToString());
}
else
{
base.Render(writer);
}
}
The times when developers should need to override ASP.Net’s natively-generated HTML are few and far between, but it’s useful to know how to do this should it be required.
Unload
The last thing that happens before the processed page gets output to the user that submitted/requested it is that the Unload Event gets called for each control on the page, then for the page itself. This is the best place to close any open connections to databases or files at the server side (either in the page level event for general connections, or in control-level Unload events where a specific control has exclusively used a particular resource during the processing of the page).
That’s pretty much it for the page life cycle. It should be noted that the life cycle for a CallBack is slightly different, but similar in most of the important respects noted above (the main difference is that Callbacks don’t involve submitting the whole page for processing, only discrete elements of it, and that consequently ViewState is therefore unaffected by Callbacks). It’s pretty amazing to think how much innovation and ingenuity has gone into making what was originally a static document delivery system into the fully-interactive medium that it’s since become.